200826) 인공지능 교내 특강
2020년 8월 26일
오늘은
....
알고리즘랩스와 Microoft Azure Machine Learning Studio와
함께하는 인공지능 교내 특강!!!
8월 26일 수요일 오후 1시부터 5시 반까지 진행하고
8월 27일 목요일 오후 1시부터 심화과정이 또 진행된다!!!
교내 특강으로 인공지능이 나온 것은
처음이고 단기라도 들어보고 싶어서 바로 신청했다!!
선착순이어서 빠르게 마감됐지만 다행히도 수강생이 되었다!!!!
빠-밤!
먼저 AI Analyst 소개 영상부터 봤다!!!

코딩 없이 만들어보는 실습 위주의 교육과정
- 인공지능 만들 때 필요한 데이터
- 데이터를 어떻게 활용하는 지
- 인공지능 모델을 개발하는 데 필요한 절차들
인공지능을 만드는 과정이 정형화 되어있다.
> 절차가 정해져 있다는 말!!!!
누구나 인공지능을 편하게 만들 수 있도록 해보자!!!
> Google, Microsoft 등의 기업 등장
> 인공지능이 빠르게 대중화되고 있다.
인공지능을 만들 수 있는 개발 툴들이 많아짐.
> 우리도 한 번 만들어보자!!!!
이론 강좌
- 연사소개
- 인공지능에 대한 전반적인 이해
- 강좌 소개
"처음 몇개의 AI 프로젝트가 성공하는 것이 가장 가치있는 AI 프로젝트들이 성공하는 것보다 중요하다."
-Andrew Ng-인공지능 프로세스 어떤 목적을 가짐
- 비즈니스 영역 탐색
- 개인보다는 특정 기업에서 많이 사용
- 비즈니스와 인공지능 기술 모두 이해할 수 있어야 함
- 비즈니스 목표 수립 (중요)
- 인공지능(기술) 관점의 목표
- 비즈니스(사업) 관점의 목표
- 데이터 수집 및 적재
- 80%의 비용과 시간이 듬
- 인공지능 PoC 모델 개발
- 인공지능 상용화 모델 개발
- 비즈니스 영역 탐색
- Auzre Machine Learning Studio
예측 분석 모델 개발을 어떻게 할 것인가
- 2014년부터 존재
- 인공지능 대중화 > 어려운 알고리즘을 활용 관점에서 안내
- 참고) KAGGLE > 여러 데이터들을 올리고 해당 데이터로 만든 플랫폼으로 심사
- AI Insight
- 증기 기관 > 산업 혁명 (1차)
- 인공지능의 가치 > 만 1.52경원 정도 된다. > 산업혁명에 비유된다
- Potential > 증기기관의 4배, 로봇의 3배, IT의 2배라고 한다
- 많은 기업들이 대부분 실패한다할 정도로 어려움
참고) Microsoft > 트위터 봇을 만들었음 (사용자들로부터 배움) > 24시간 후, 욕밖에 안하게 됨 > 실패
ROI가 잘 안나와서 (투자 대비 수익), 데이터가 너무 많아서, 팀의 역량을 초과해서 등의 문제로 실패 - MathUp(?)에서 만든 3가지
- Insights (특정 업무에 대한 직관력)
- Integration (다른 시스템과 연결되야 함)
- Implementation
- Key Insights Made
해결하려는 영역에 대한 이해가 필요!!!
- Predictions were wrong
예측과의 차이를 보고 그 차이를 줄여나가야 함
왜 안나오지에 대한 가설의 문제를 찾아야 함
사업에 대한 이해 필요 - Need to build a seperate model for each plant (도메인)
- Plant's operationg state changes each year (도메인)
- Training data was biased (데이터)
- Predictions were wrong
- Machine Learning인공지능 : 사람에 의하여 만들어진 생각할 수 있는 능력
생각: 특정 사안에 대해 경험에 의거하여 스스로 판단할 수 있어야 함
기계학습: 컴퓨터가 학습을 통해 결과를 내보내는 것기계학습이 왜 유용한가?- 사람이 할 것을 대신 해줌
- 암 진단
- 자율주행
- 제조과정 디자인 및 평가
- 기타
- 사람에게 통찰을 제공해줄 수 있다
- 환자의 데이터 분석을 통한 건강 관리
- 잘못된 카드 사용
- 주가 데이터 분석을 통한 주가 예측 및 거래 자동화
- 개인화
- 넷플릭스, 유투브, 페이스북, 구글 등
- 사람이 할 것을 대신 해줌
- 머신러닝의 4가지 대표적인 접근
- 지도 학습 : "잘 정리된" 데이터를 기반으로 패턴을 파악함
- 비지도 학습 : "잘 정리된"데이터 없이 패턴을 파악함
- 강화 학습 : 환경과의 상호작용을 통해 최적의 전략을 찾음
- 딥러닝 : 인공신경망을 활용하여 학습함
- 인공지능 개발
- Data collection
- Exploratory Data Analysis (EDA)
- Feature enginerring
- Building a model
- Evaluating the model
- Interpreting the results
- Improving the model
- 인공지능의 3가지 활용
- 회귀 (Regressiong)
특정한 값을 예측하는 것 - 분류 (Classification)
- 추천 (Recommendation)
- 회귀 (Regressiong)
- 강좌 소개
드디어
실습 시작!!!!!!!!!!!
첫 번째 실습의 데이터는
Azure Machine Learning Studio에서 제공하는 Sample Data인
Automoblie price data (Raw) 를 사용하기로 했다!!!
Exploratory Data Analysis (EDA) 작업
- 데이터를 시각화해서 보는 것이 좋다
- Missing Value의 정도와 중요도를 보고 데이터를 제거하거나 채워준다!
- 너무 정비례 하는 데이터는 제거해준다 > 오히려 복잡도를 높일 뿐


Missing Value 데이터를 채워줄 때
Replace .....
- 컬럼의 평균을 채우는 것이 Mean
- 중앙값이 Medium
- unique Value가 적을 때는 최빈값 Mode 사용
그 외에 Remove entire Row 선택
> Missing Value가 하나도 없는 것을 확인할 수 있다.


이제는 데이터셋을 분류해야할 차례이다!!!
보통 만들어진 데이터셋 중의
- 70%는 트레이닝셋
- 30%는 테스트셋
에 할당한다!!!
> Split Data 사용

이제 Machine Learning으로 학습을 시킬 차례이다
우리는 Train Model과 Regression(회귀) 모델의 Linear Regression 모델을 사용하기로 했다!!!

Train의 짝꿍은 Score!!!!
이제 Score Model을 연결해본다
Score Model에 Train한 데이터와 Train하지 않은 데이터를 연결한다
그리고 Price를 Score로 학습한 결과를 보자!!!!
Run 한 결과
- Lable 하나가 생김 > Score Labels
- Trained Model이 학습한 결과로 예측한 값이 바로 Score Labels
- Score와 비교해보면서 얼마나 오차가 있는지 확인!!!

이후, Evaluate Model 을 사용해서
Score Model의 성능을 평가한다
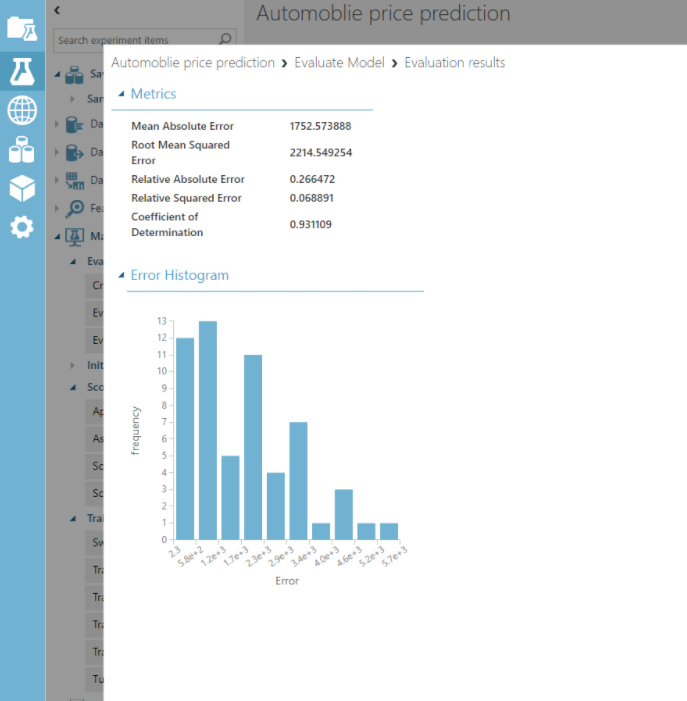
빠-밤!!
첫 번째 실습이 다 끝났다!!
두 번째 실습은 조금 귀찮으니까... 블로그에는 작성하지 않고 하려고 한다........
집중력이 동난 것 같다....
내일 어떻게 또 강의를 들을지 조금 걱정이다....